Clustered Index, Non Clustered Index
데이터베이스에서 인덱스는 데이터를 빠르게 찾기 위한 핵심 기능이다. 책의 목차나 색인과 같은 역할을 하며, 원하는 데이터를 빠르게 찾을 수 있게 도와준다.
인덱스는 크게 클러스터드 인덱스와 넌클러스터드 인덱스로 나뉜다.
클러스터드 인덱스
CREATE TABLE users (
id INT PRIMARY KEY, -- 자동으로 클러스터드 인덱스
name VARCHAR(50)
);
클러스터드 인덱스는 데이터를 물리적으로 정렬하여 저장하는 방식이다. 여기서 '클러스터드(Clustered)'란 '군집화된', '모여있는'이라는 의미로, 실제 데이터가 인덱스 순서대로 물리적으로 함께 모여있다는 것을 뜻한다. 이는 마치 도서관의 책들이 도서번호 순서대로 실제로 정렬되어 있는 것과 같은 개념이다.
실제 디스크에서는 데이터가 인덱스 순서대로 정렬되어 저장된다. 예를 들어, id가 1, 3, 2인 순서로 데이터를 입력해도 디스크에는 1, 2, 3 순서로 재배열된다. 이러한 물리적 정렬은 검색 성능을 크게 향상시키지만, 새로운 데이터가 추가되거나 기존 데이터가 수정될 때 재정렬이 필요하므로 입력/수정/삭제 작업의 성능은 상대적으로 떨어진다.
MySQL의 InnoDB 엔진에서는 기본적으로 PRIMARY KEY가 클러스터드 인덱스가 된다. 테이블당 오직 하나만 생성할 수 있으며, 리프 노드에 실제 데이터가 저장된다. 이러한 특성 때문에 PRIMARY KEY를 기준으로 한 검색이 매우 빠르며, 특히 범위 검색에서 뛰어난 성능을 보인다.
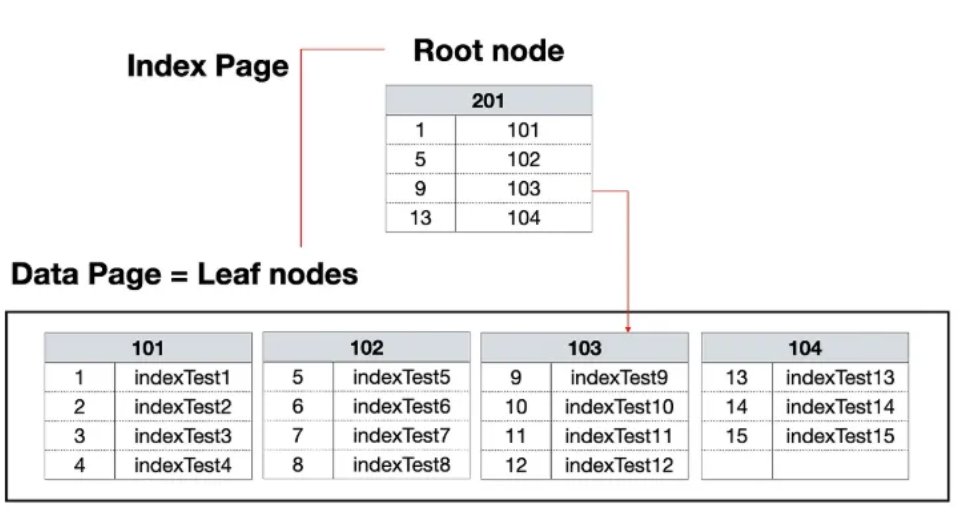
또한 클러스터드 인덱스는 이미 데이터가 정렬된 상태로 저장되기 때문에 leaf level의 인덱스 테이블이 필요치 않다.
즉, 클러스터드 인덱스는 넌 클러스터드 인덱스보다 DB 용량을 덜 차지한다.
PRIMARY KEY가 없는 경우
간혹, 테이블에 PRIMARY KEY가 없는 경우가 있는데, 그럴 경우 mysql에서는 다음과 같은 규칙으로 클러스터드 인덱스를 선택한다.
PRIMARY KEY가 없는 경우의 처리 순서
- UNIQUE 인덱스 중 첫 번째로 생성된 NOT NULL 인덱스가 클러스터드 인덱스가 된다
- 위 조건을 만족하는 인덱스도 없다면, 자동으로 보이지 않는 바이트 크기의 'Row ID' 컬럼을 생성하여 이를 클러스터드 인덱스로 사용한다.
넌클러스터드 인덱스

CREATE INDEX idx_name ON users(name);
넌클러스터드 인덱스는 데이터와 별도로 존재하는 인덱스 구조이다. 여기서 '넌클러스터드(Non-Clustered)'란 '군집화되지 않은'이라는 의미로, 데이터가 물리적으로 정렬되지 않고 논리적인 순서만 가진다는 것을 뜻한다. 이는 마치 도서관의 컴퓨터 검색 시스템처럼 책의 실제 위치만 알려주는 것과 같은 개념이다.
실제 데이터는 정렬되지 않은 상태로 저장되며, 인덱스는 데이터의 위치를 가리키는 포인터를 가진다. 예를 들어, name으로 인덱스를 만들면 name은 정렬되어 있지만, 실제 데이터는 원래의 저장 위치를 그대로 유지한다. 이러한 구조는 데이터 변경이 자유롭지만, 데이터를 찾을 때는 인덱스를 거쳐 실제 데이터에 접근해야 하므로 클러스터드 인덱스보다 검색 속도가 상대적으로 느리다.
하나의 테이블에 여러 개의 넌클러스터드 인덱스를 생성할 수 있다. 이는 다양한 검색 조건을 지원할 수 있다는 장점이 있지만, 각 인덱스가 추가 저장 공간을 필요로 하고 데이터가 변경될 때마다 모든 인덱스를 갱신해야 하는 단점이 있다. 주로 WHERE 절에서 자주 사용되는 컬럼이나 JOIN 연산에 사용되는 컬럼에 넌클러스터드 인덱스를 생성한다.
참고
[MySQL] 프라이머리 키(PK, Primary Key)에 대해 쉽고 완벽하게 이해하기 - MangKyu's Diary
[MySQL] 프라이머리 키(PK, Primary Key)에 대해 쉽고 완벽하게 이해하기
이번 내용은 RealMySQL 8.0 책을 보면서 추가적으로 공부하여 정리한 내용입니다. 따라서 MySQL의 InnoDB가 아닌 경우에는 다를 수 있으니 참고 부탁드립니다. 1. 프라이머리 키(PK, Primary Key)와 클
mangkyu.tistory.com
클러스터드 인덱스와 넌 클러스터드 인덱스 차이점
클러스터드 인덱스와 넌 클러스터드 인덱스 차이점 클러스터 인덱스는 데이터 위치를 바로 알기 때문에 그 데이터로 바로 접근할 수 있고, 넌 클러스터 인덱스는 인덱스 페이지를 한번 거쳐서
velog.io
클러스터드 인덱스와 넌 클러스터드 인덱스 :: 혹독한 겨울에 자라 배울수록 겸손한 보리
클러스터드 인덱스와 넌 클러스터드 인덱스
참고 : https://lng1982.tistory.com/144 생각 : 클러스터드 인덱스는 테이블당 하나만 생성되며 pk가 이 클러스터드 인덱스다. 클러스터드 인덱스는 정렬되어있기 때문에 leaf level의 인덱스가 필요하지 않
cupeanimus.tistory.com